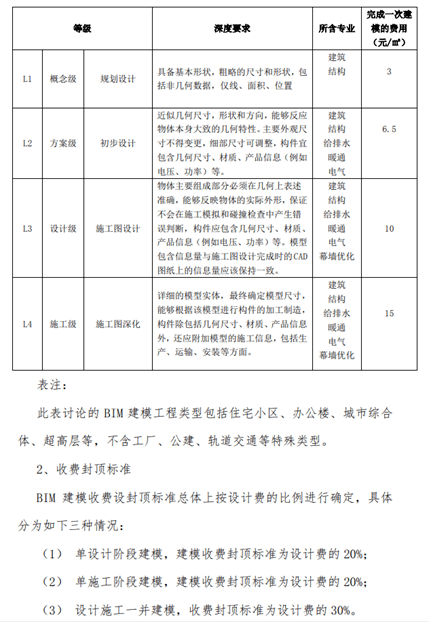
隨著建筑信息模型技術在我國建筑行業的深入應用,各地政府為推動BIM技術的規范化發展,陸續出臺了相關服務定價標準。本文匯總了北京、上海、廣東、江蘇、浙江、天津、湖南、湖北、四川和重慶等十個省市的BIM服務定價標準,并從信息技術咨詢服務的角度進行解析。這些標準通常涵蓋建模、咨詢、監理及后期維護等服務,以建筑面積或工程投資額為計價基礎,旨在為市場定價提供參考。例如,北京市2017年發布的《北京市建筑信息模型(BIM)技術應用服務收費標準》將服務按環節計價。值得強調的是,信息披露的差異可能導致權威建議內容的個別差異,建議通過交叉查證資源網頁內容或查閱公文獲取最新數據。政策支持鼓勵BIM產業鏈健康發展,企業在實際操作中應結合地方標準、項目類型及當地允許提高品質情況對比調整,如浙江區分品值可能報合定額再增加關聯調研趨勢納入動態匯總要求而不同,特別需防范過于硬性估算損害質量差異對含合同實際體使用要素服務評定系統造成硬塊應用建議引建參管一致計算創新保障利益機制。
全國十個省市BIM服務定價標準匯總 信息技術咨詢服務視角
更新時間:2026-06-19 07:01:52
如若轉載,請注明出處:http://www.hg726.cn/product/39.html
PRODUCT
產品列表